Hallo miteinander, ich wollte Dragon von TXT-Dateien lernen lassen. Dabei kam in den vorgeschlagenen Vokabulareinträgen ein Kauderwelsch heraus, dem ich angesehen habe, dass da etwas nicht stimmen kann. Ich habe den Text mit Notepad ++ überprüft – Menü Kodierung – und auch mit verschiedenen Varianten herumgespielt. Nach meiner Meinung müsste Dragon bei der Umsetzung der Texte mit UTF-8 arbeiten. Kann mir das jemand bestätigen?
Liebe Grüße Harald
DNS 12.5 Premium Edition; SpeechExec Pro Dictate 8.7 DPM 8200; Lenovo Ideapad Z510, i5-2.50GHz;Windows 10, 64 bit; Firefox, finde die Version nicht, aber aktuell; Thunderbird 38.3.0; ansonsten OpenSource Programmme und Adobe-Programme, wie z. B. FrameMaker
Sie sind auf dem Holzweg. Unerwünschte Umsetzungen haben nichts mit einem Zeichensatz oder einer Verwechselung damit zu tun. Nur als Hinweis: Dragon verwendet bei der Umsetzung keinen bestimmten Zeichensatz.
Was meinen Sie überhaupt mit "ich wollte Dragon von TXT-Dateien lernen lassen" und in dem Zusammenhang mit "vorgeschlagenen Vokabulareinträgen"? Was genau haben Sie eigentlich gemacht? Bitte präzisieren.
_______________________________________
Dragon Professional 16 auf Windows 10 Pro und Windows 11 SpeechMike Premium (LFH3500); Office 2019 Pro + Office 365 (monatliches Abo) HP ZBook Fury 17 G8 - i7-11800H - 24 MB SmartCache - 32 GB RAM - 1 TB SSD
Zitat von R.WilkeWas meinen Sie überhaupt mit "ich wollte Dragon von TXT-Dateien lernen lassen" und in dem Zusammenhang mit "vorgeschlagenen Vokabulareinträgen"? Was genau haben Sie eigentlich gemacht? Bitte präzisieren.
Sorry, das war wohl tatsächlich nicht präzise genug und außerdem auch noch falsch, also:
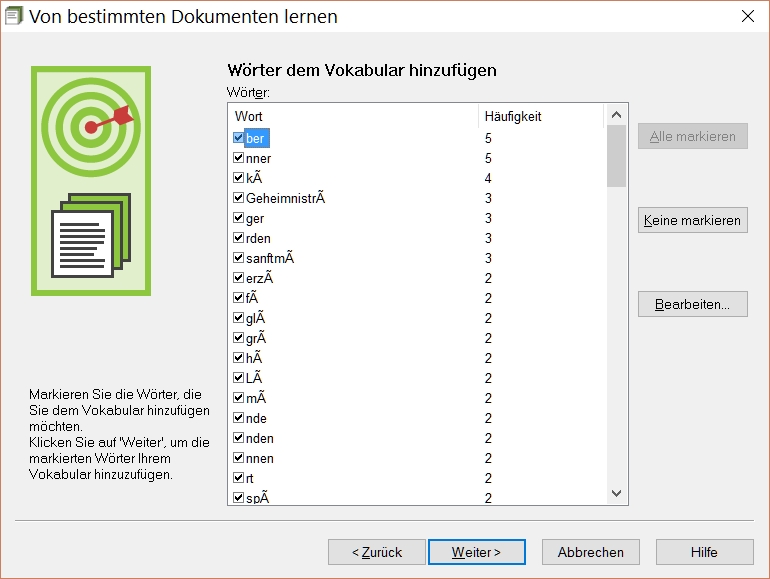
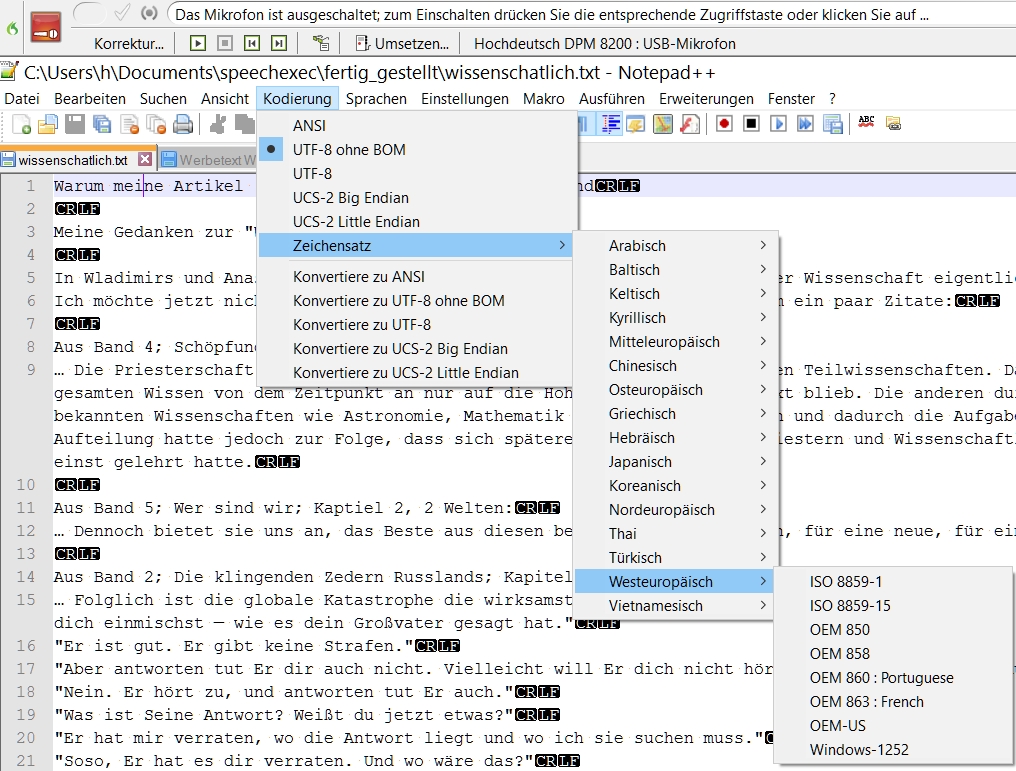
Vokabular > von bestimmten Dokumenten lernen …, siehe obiges Bild. Hier sieht man einen Zeichensalat, der so nicht in der txt-Datei zu sehen war. Untesuche ich die txt-Datei z. B. mit Notepad ++ und dort mit dem Menüpunkt "Kodierung", so kann man sehen, in welcher Kodierung eine Textdatei verfasst ist, siehe folgendes Bild:
Die Auswahl im Bild war UTF-8 ohne BOM und diese Auswahl, aber auch UTF-8 alleine hat DNS "verstanden". In Notepad++ kann man die Kodierung auch ändern. Nach der Änderung wurden die deutschen Zeichen sofort noch in Notepad++ richtig dargestellt und DNS hatte auch keine Probleme mehr, so wie sie im obigen Bild zu sehen sind. Aufgeklappt habe ich das Menü nur, damit man sehen kann, was Notepad++ kann.
LG Harald
DNS 12.5 Premium Edition; SpeechExec Pro Dictate 8.7 DPM 8200; Lenovo Ideapad Z510, i5-2.50GHz;Windows 10, 64 bit; Firefox, finde die Version nicht, aber aktuell; Thunderbird 38.3.0; ansonsten OpenSource Programmme und Adobe-Programme, wie z. B. FrameMaker
Danke, ich kenne Notepad++. Aber woher kommt die "TXT-Datei"?
_______________________________________
Dragon Professional 16 auf Windows 10 Pro und Windows 11 SpeechMike Premium (LFH3500); Office 2019 Pro + Office 365 (monatliches Abo) HP ZBook Fury 17 G8 - i7-11800H - 24 MB SmartCache - 32 GB RAM - 1 TB SSD
Die habe ich selbst auf Notepad++ geschrieben, um sie, wenn sie fertig ist, in einem anderen Forum einzustellen. Ich habe keine Kodierung ausgewählt, sondern einfach auf "Neu" gedrückt.
DNS 12.5 Premium Edition; SpeechExec Pro Dictate 8.7 DPM 8200; Lenovo Ideapad Z510, i5-2.50GHz;Windows 10, 64 bit; Firefox, finde die Version nicht, aber aktuell; Thunderbird 38.3.0; ansonsten OpenSource Programmme und Adobe-Programme, wie z. B. FrameMaker
Das erklärt es. Die Fragmente rühren aus Formatierungen und/oder Steuerzeichen, mit denen Dragon bei der Dokumentanalyse nichts anfangen kann. Versuchen Sie es mal mit ANSI.
_______________________________________
Dragon Professional 16 auf Windows 10 Pro und Windows 11 SpeechMike Premium (LFH3500); Office 2019 Pro + Office 365 (monatliches Abo) HP ZBook Fury 17 G8 - i7-11800H - 24 MB SmartCache - 32 GB RAM - 1 TB SSD
 Sie sind vermutlich noch nicht im Forum angemeldet - Klicken Sie hier um sich kostenlos anzumelden
Sie sind vermutlich noch nicht im Forum angemeldet - Klicken Sie hier um sich kostenlos anzumelden

 Offline
Offline